
Arquitecturas de Datos Real-Time
¿Real-time o procesamiento batch? Sabemos que la implementación de arquitecturas de datos en tiempo real es una opción cada vez más accesible.
En este artículo, detallamos cuáles son las herramientas para bajar el costo y la complejidad de la implementación de real-time y qué empresas necesitan implementarlo sí o sí. Si existe la opción de acceder a datos en tiempo real, y su costo y complejidad son similares al procesamiento batch, ¿por qué no hacerlo?
Real-time: qué hay que tener en cuenta antes de empezar a considerar su integración
La creación de sistemas y arquitecturas de datos en tiempo real –mejor conocidas en inglés como real-time– son una evolución natural en la industria. Si se pueden obtener datos procesados en tan solo milisegundos en lugar de esperar horas, no habría por qué esperar. Pero es un trade-off.
A lo largo de este artículo, discutiremos si vale la pena invertir en real-time, cuáles son sus beneficios, cuándo este sistema tiene sentido y si es realmente el futuro del sector.
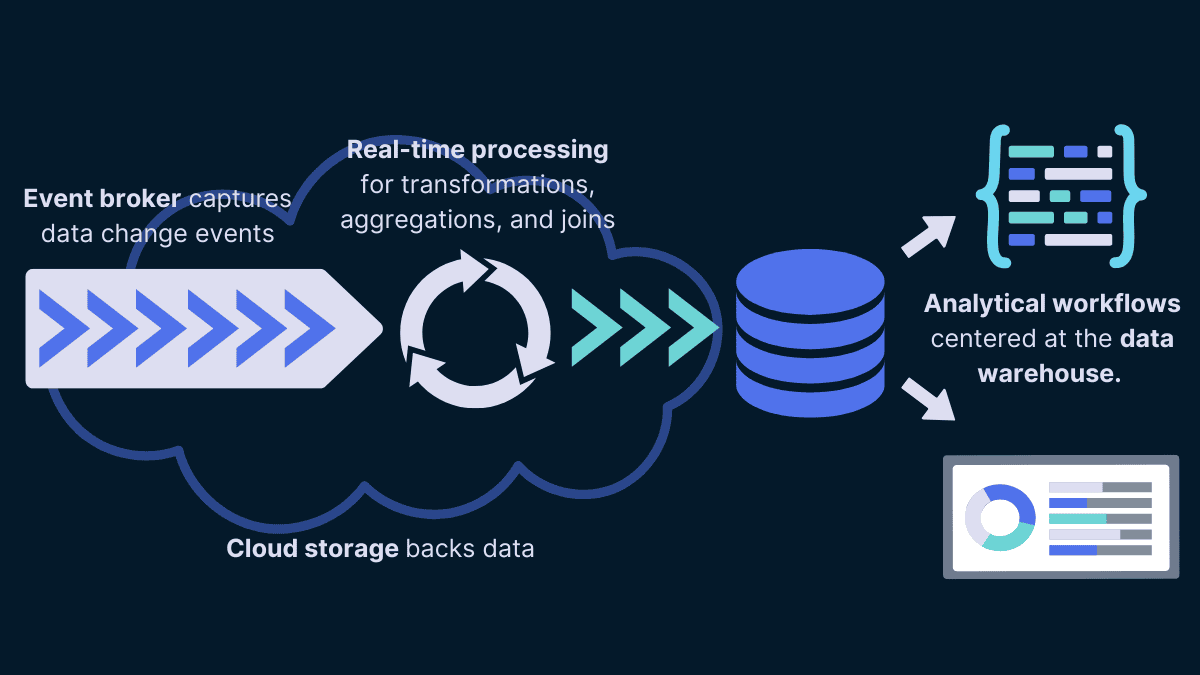
Complejidad y costos
En la actualidad, implementar un sistema en tiempo real suele ser más costoso en términos de servicios cloud, debido a la infraestructura que se necesita y al tiempo de implementación.
El real-time implica gestionar tecnologías como Apache Flink, Kafka, entre otras, que requieren habilidades especializadas y la configuración adecuada para manejar la alta disponibilidad, baja latencia y el procesamiento continuo de flujos de datos.
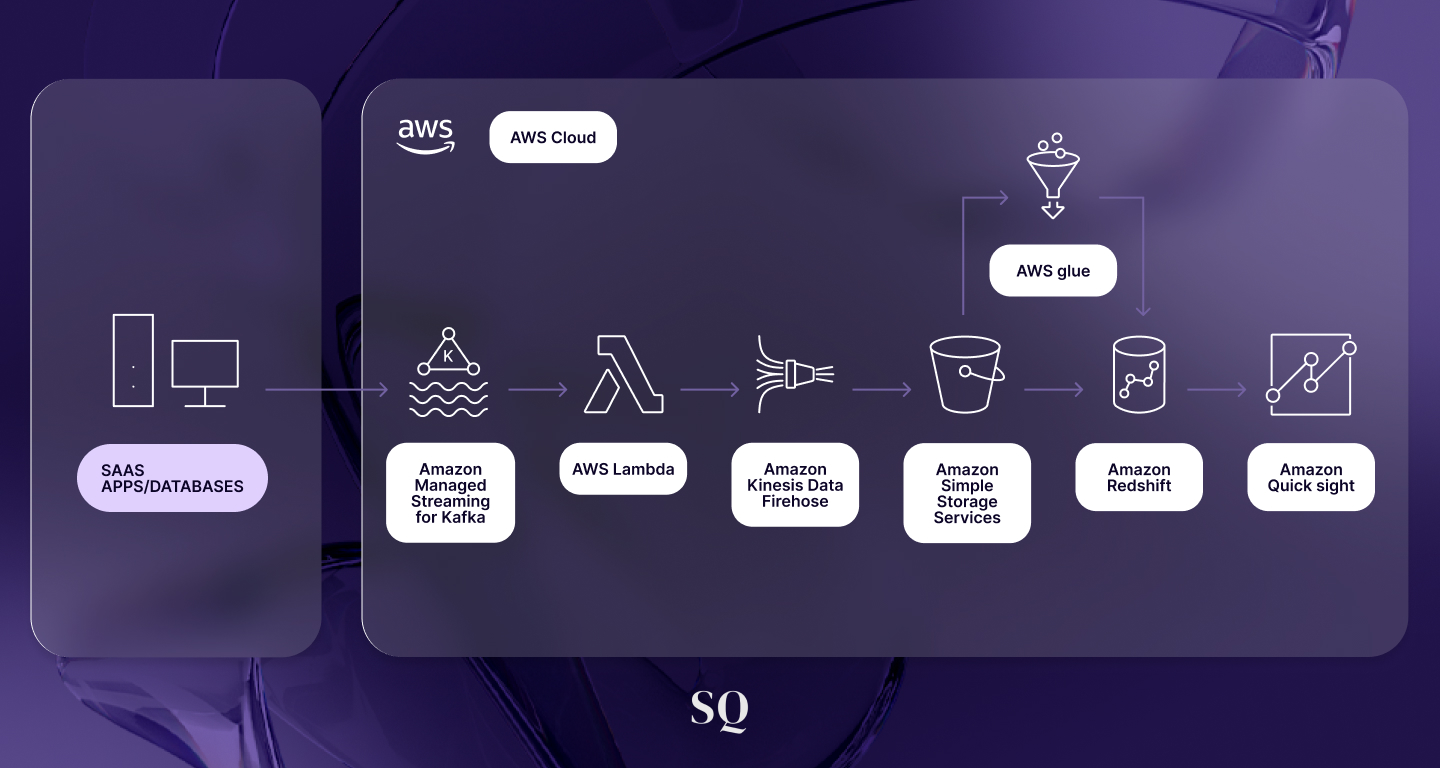
Por ejemplo, desde Squadra Labs, hemos implementado este tipo de arquitecturas para grandes empresas utilizando estas tecnologías. Augusto De Nevrezé escribió de forma muy clara el caso de cómo lo construimos utilizando AWS Managed Apache Flink. El artículo completo se encuentra en este enlace.
En esta línea, si los factores costos y complejidad fueran iguales al procesamiento batch, sin dudas, la elección sería clara: todo se haría en tiempo real. Tanto sistemas financieros, monitoreo de infraestructuras, aplicaciones de IoT, o plataformas de comercio electrónico elegirían el real-time sin cuestionamiento alguno.
Por esta razón, la verdadera pregunta es si ese esfuerzo adicional de implementación vale la pena en todos estos contextos. Para responderla, habría que evaluar cada empresa y cada caso en particular, examinando en profundidad si realmente se necesitan datos inmediatos para los procesos, o si trabajar en lograr una mayor latencia es suficiente.
En resumen, esto depende de la frecuencia del consumo de los datos. No es necesario refrescar la información cada 100 milisegundos cuando la misma se accede una vez por día. Cuando un procesamiento en tiempo real es necesario, si bien requiere algunos conocimientos extra, no es tan difícil implementarlo como solía ser.
Es importante destacar que el desarrollo de herramientas y plataformas modernas ha facilitado enormemente la implementación de arquitecturas en tiempo real. Servicios como Kafka, Flink y soluciones cloud en AWS o Google Cloud han reducido las barreras de entrada. Por ejemplo, al integrar Apache Flink con Kafka y PostgreSQL usando Docker Compose, se puede crear un flujo continuo de procesamiento de datos, filtrando y almacenando información de manera eficiente. Este tipo de configuración simplifica la adopción de arquitecturas en streaming, permitiendo a las empresas aprovechar las ventajas sin tener que mantener grandes equipos de infraestructura.
Real-time: cuándo tiene sentido y cuándo no
En principio, es clave enfocarse en industrias y verticales donde el real-time tiene mucho sentido, debido a la inmediatez de sus operaciones. A continuación, analicemos de manera conjunta dos casos para diferenciar cuándo sí es necesario el real-time y cuándo no.
Si los datos van a ser utilizados para mover otros datos, automatizar y coordinar procesos que dependen de decisiones instantáneas —como la detección de fraude en una fintech, el control en tiempo real de sensores Internet of Things (IoT)— adoptar el real-time puede ser un diferenciador competitivo.
Sin embargo, no siempre puede que valga la pena o sea necesario crear un sistema real-time. Aquellas empresas que estén pensando en adoptar la tecnología para el análisis de tendencias a largo plazo o reportes financieros, donde el objetivo es analizar grandes volúmenes de datos históricos, la respuesta es no es tan necesario. Es decir, si los datos solo van a ser usados para generar reportes o para alimentar dashboards que se consultan una vez al mes o incluso una vez por día, el real-time no aportará ningún valor adicional.
¿Qué tan rápido se necesitan los datos? ¿Qué se va a hacer con los datos? Dos preguntas claves a la hora de entender el valor de crear un pipeline o implementar arquitectura real-time.
El costo de cambiar
Hoy en día, la mayoría de los pipelines, ETL y sistemas son en batch. Es por esta razón que las empresas deben evaluar cuidadosamente si el esfuerzo de migrar a una arquitectura en tiempo real está justificado.
¿Por qué? Migrar arquitecturas que fueron desarrolladas en tiempos en los que el batch no era la norma hacia un modelo de streaming implica costos tecnológicos y tiempo. Además, se traduce a un cambio significativo dentro de los equipos de datos que tendrán que crear y monitorear estos sistemas de manera continua.
A diferencia de los sistemas batch, donde los fallos pueden ser gestionados de manera más controlada, en el tiempo real cualquier interrupción tiene un impacto inmediato en las operaciones. Esto significa que las empresas necesitarán tener un enfoque más robusto para el monitoreo y mantenimiento continuo. En resumen, mantener una arquitectura en tiempo real puede añadir complejidad operativa.
En este sentido, desde Squadra, consideramos prioritario implementar herramientas de observabilidad. Es muy importante monitorear el estado de nuestros pipelines ya que sobre los mismos viajan datos de manera continua, por lo tanto, prácticamente no se permiten fallas de infraestructura.
Por último, es importante diseñar un marco de desarrollo adecuado para no impactar cambios sobre la infraestructura productiva que afecten la calidad de los datos transportados ya que, muchas veces, la data que viaja en real-time no puede ser reprocesada.
Casos en los que se aplica real-time
Actualmente, existen sectores donde la adopción del real-time tiene un impacto directo y significativo en las operaciones diarias.
Uno de los ejemplos más claros es la industria fintech, que necesita de procesamiento en tiempo real para manejar pagos y puntos de venta (POS). Deben aprobar transacciones de forma inmediata, y darle visibilidad a los usuarios de sus saldos y otra información.
Por otro lado, en cuanto a grandes empresas, todas se benefician de algún proceso con inmediatez de datos. Un claro ejemplo es la app de delivery de comidas como pueden ser Uber Eats, Rappi o PedidosYa, donde la coordinación en tiempo real es esencial. Tanto los clientes que hacen pedidos, como los repartidores y restaurantes, dependen de datos inmediatos para garantizar una entrega rápida y eficiente.
En los casos anteriormente mencionados un sistema de batch no sería suficiente ya que retrasaría las actualizaciones y afectaría la experiencia del usuario.
Otros ejemplos son las empresas de telecomunicaciones o de manufactura, que utilizan datos que salen de dispositivos IoT. Estas compañías necesitan datos inmediatos sobre su rendimiento e identificar problemas rápidamente con el objetivo de minimizar los tiempos de inactividad y optimizar la producción.
Conclusión ¿El Futuro es Real-Time?
El avance de las herramientas y plataformas está reduciendo el umbral de entrada, lo que hace que el procesamiento en tiempo real sea una opción cada vez más accesible para muchas empresas. Lógicamente, es necesario evaluar cada caso en función de la necesidad y el valor que aportaría contar con los datos de manera inmediata. Sin embargo, si la tendencia continúa y existe la posibilidad de acceder a datos en tiempo real con un costo y complejidad comparables al procesamiento batch, la pregunta es: ¿por qué no hacerlo?