
Apache Iceberg - Gestión de datos en empresas modernas
La gestión de datos en las empresas modernas ha evolucionado considerablemente en las últimas dos décadas, pasando de simples bases de datos a sistemas avanzados diseñados para manejar volúmenes de información sin precedentes. Este cambio ha sido impulsado por el crecimiento exponencial de datos, alimentado por dispositivos móviles, el Internet de las Cosas (IoT) y diversas actividades en línea. Con este aumento en el volumen de datos, los métodos tradicionales de gestión se encontraron con limitaciones, lo que llevó a la necesidad de soluciones innovadoras como Apache Iceberg, un formato de tablas potente para data lakes.
Comprender los orígenes de la gestión de grandes volúmenes de datos nos ayuda a valorar dónde estamos hoy. A principios de los 2000, sistemas como Apache Hadoop marcaron el comienzo de la gestión escalable de datos, introduciendo el almacenamiento distribuido y el procesamiento paralelo con MapReduce. Hadoop permitía distribuir los datos en múltiples máquinas, lo que resolvía el problema del almacenamiento a gran escala. Sin embargo, la complejidad de escribir rutinas en MapReduce y las limitaciones en el rendimiento del procesamiento por lotes pronto se hicieron evidentes.
Para abordar estas limitaciones, se desarrolló Apache Hive. Hive proporcionaba una capa de abstracción que permitía a los usuarios escribir consultas similares a SQL, que luego Hive traducía en trabajos de MapReduce. Si bien esta innovación simplificó los procesos de consulta de datos, trajo consigo nuevos desafíos a medida que las organizaciones comenzaron a producir aún más datos, surgiendo la necesidad de utilizar soluciones de almacenamiento en la nube como Amazon S3. La dependencia de Hive en HDFS para el almacenamiento y su incapacidad para procesar consultas en tiempo real lo hicieron inadecuado para las demandas modernas.
Este crecimiento en la complejidad de la gestión de datos generó nuevos paradigmas. Las empresas necesitaban cada vez más almacenar enormes cantidades de datos en soluciones basadas en la nube, que fueran más económicas y escalables, mientras mantenían la flexibilidad y el rendimiento. El punto de inflexión llegó con el desarrollo de arquitecturas data lakehouse y herramientas como Apache Iceberg.
¿Por qué Apache Iceberg?
Apache Iceberg aborda los desafíos fundamentales de los sistemas tradicionales de gestión de datos, especialmente en el ámbito de los data lakes a gran escala. A diferencia de los sistemas anteriores que tenían problemas de rendimiento y flexibilidad, Iceberg introduce un formato de tabla que separa el almacenamiento del cómputo, lo que permite a las empresas aprovechar tanto el procesamiento por lotes como el procesamiento en tiempo real a través de múltiples motores.
En su núcleo, Iceberg está diseñado para proporcionar varios beneficios clave:
-
Propiedad de la Metadata: Iceberg permite a las organizaciones poseer su metadata, evitando el temido bloqueo de proveedores. Esto brinda la flexibilidad de usar cualquier motor de procesamiento, como Apache Spark, Dremio o Trino. Al desacoplar la metadata del almacenamiento, Iceberg asegura que las empresas no estén restringidas a proveedores o sistemas específicos, ofreciendo portabilidad y sostenibilidad a largo plazo.
-
Capacidades de Data Warehouse en un Data Lake: Tradicionalmente, los data lakes ofrecían almacenamiento, pero carecían de las funciones avanzadas de los data warehouses, como la capacidad de realizar actualizaciones, eliminaciones y la evolución de esquemas. Iceberg introduce estas funcionalidades de data warehouse en los data lakes, convirtiéndose en una solución híbrida poderosa. Por si fuera poco, Iceberg admite “time travel”, una funcionalidad que permite a los usuarios consultar versiones históricas de los datos, y facilita la gestión eficiente de cambios de esquema.
-
Rendimiento y Mantenimiento: Uno de los mayores puntos débiles de los sistemas tradicionales es la ineficiencia en la actualización de pequeños conjuntos de datos y la dificultad para mantener el rendimiento a largo plazo. Iceberg resuelve esto al habilitar consultas rápidas a través de su enfoque basado en metadata. En lugar de escanear particiones o directorios completos de datos, Iceberg organiza los datos a través de snapshots y manifiestos para identificar solo los archivos necesarios para una consulta, mejorando significativamente el rendimiento.
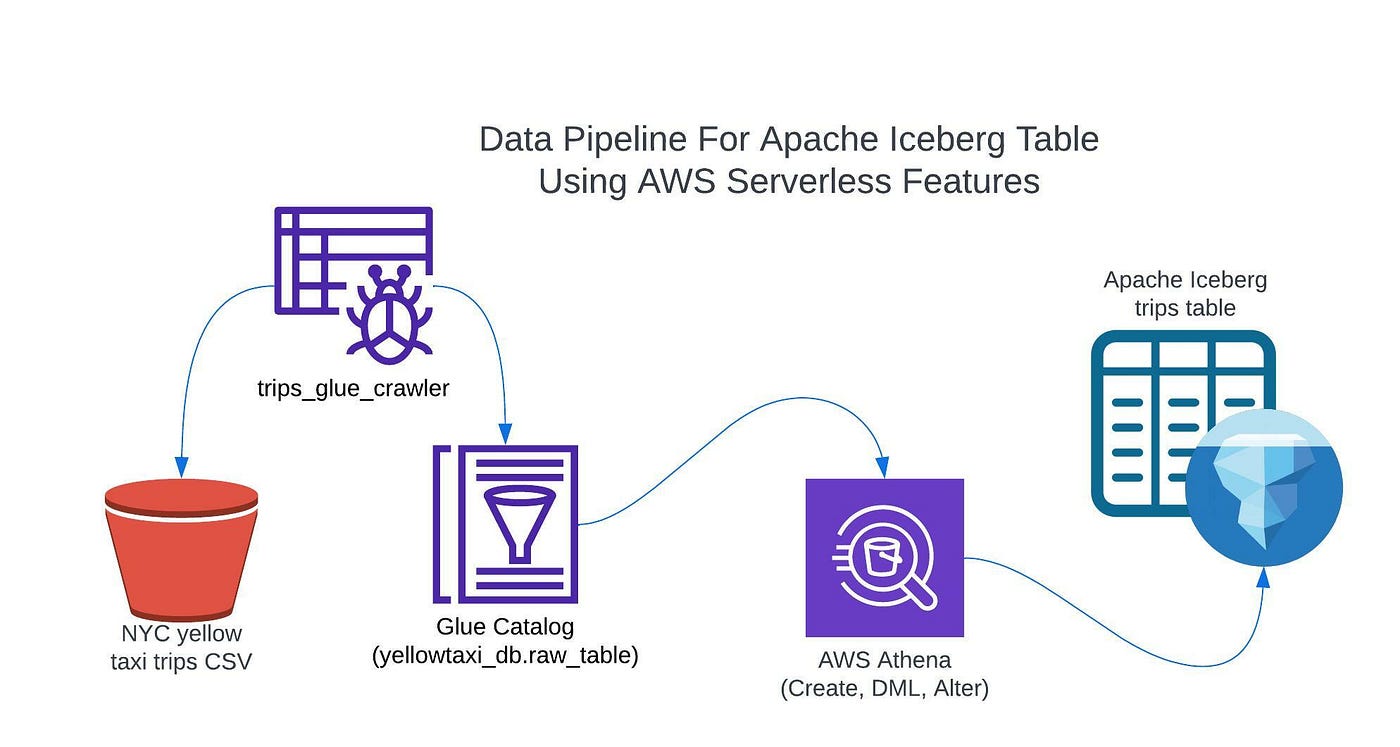
La evolución del Data Lakehouse
El concepto de un data lakehouse combina la escalabilidad y asequibilidad de los data lakes con la estructura y el rendimiento de los data warehouses. Iceberg juega un papel crucial en hacer que esta arquitectura sea una realidad al proporcionar el “pegamento” que une estos componentes. En una configuración típica de data lakehouse, los datos crudos se almacenan en un data lake (utilizando almacenamiento en la nube como Amazon S3), pero se pueden consultar y procesar con la velocidad y eficiencia típicas de un data warehouse.
Esta arquitectura ofrece varias ventajas:
-
Reducción de la duplicación de datos: En las arquitecturas tradicionales, los datos se copian varias veces—desde los sistemas operacionales al data lake, luego al data warehouse y, en algunos casos, a diferentes data marts. Cada copia aumenta el riesgo de deriva de datos, donde diferentes versiones de los mismos datos se vuelven inconsistentes. El data lakehouse elimina estas copias redundantes, permitiendo a las organizaciones trabajar directamente con su data lake para análisis.
-
Eficiencia de costos: Los data lakes son mucho más baratos de operar que los data warehouses, especialmente a gran escala. Al implementar Iceberg, las empresas pueden obtener el mismo nivel de funcionalidad que esperarían de un data warehouse, sin los costos asociados de almacenamiento duplicado.
-
Flexibilidad y herramientas: Uno de los beneficios clave de Iceberg y del modelo data lakehouse es la capacidad de utilizar una variedad de herramientas. Ya sea Dremio para consultas interactivas rápidas o Spark para procesamiento a gran escala, las organizaciones pueden elegir la mejor herramienta para cada tarea sin quedar bloqueadas en una única plataforma.
¿Por qué deberían los ingenieros de datos prestar atención a Iceberg?
Para los ingenieros de datos, Iceberg representa una oportunidad para mejorar significativamente la forma en que gestionan, procesan y gobiernan los datos. Con Iceberg, los ingenieros pueden:
- Gestionar conjuntos de datos masivos sin preocuparse por la degradación del rendimiento a medida que el volumen de datos crece.
- Beneficiarse de características avanzadas como el “time travel” y la evolución de esquemas, que facilitan el mantenimiento y la actualización de conjuntos de datos a lo largo del tiempo.
- Evitar las complejidades de los sistemas tradicionales, que requerían un conocimiento profundo de las estructuras de archivos, particiones y disposiciones de almacenamiento. Con Iceberg, el sistema optimiza automáticamente estos componentes.
Además, Iceberg simplifica la gobernanza de datos. Al mantener una capa de metadata integral, permite a los ingenieros rastrear cambios a lo largo del tiempo, garantizando la integridad de los datos y el cumplimiento de regulaciones. Esto incluye la capacidad de revertir a versiones anteriores de los datos, mantener un registro histórico de todos los cambios y asegurar el cumplimiento de ACID, incluso a gran escala.
El futuro de la gestión de datos
A medida que las organizaciones continúan generando volúmenes de datos cada vez mayores, la necesidad de soluciones escalables, eficientes y flexibles para la gestión de datos seguirá creciendo. Apache Iceberg está bien posicionado para ser un pilar en este futuro, ofreciendo las herramientas necesarias para construir una arquitectura de datos moderna, abierta y preparada para el futuro.
Con el auge de la inteligencia artificial y el machine learning, tener datos limpios y bien gestionados es más importante que nunca. Por lo tanto, los ingenieros de datos juegan un papel crítico en habilitar esta transformación adoptando tecnologías como Iceberg para gestionar la creciente complejidad de los data lakes.
En resumen, Apache Iceberg es mucho más que un formato de tablas; es una solución a los desafíos más grandes que los ingenieros de datos enfrentan hoy en día. Su capacidad para combinar lo mejor de los data lakes y data warehouses lo convierte en una herramienta esencial para cualquier organización que busque aprovechar al máximo su potencial de datos.